
RAGs To Riches (i.e. Agents) in 7 steps
A gentle intro to the world of AI Agents with PARMeSAN

Ahh, "agents" - the AI world's favorite buzzword of 2024. It seems everyone has an agent these days and there’s so much giddy activity around the concept, yet the term is loosely defined, there’s tons of vaporware, and nobody has nailed product-market fit. Dare I say, some days in the wee hours of dawn, I quietly wonder whether the hype around agents is reminiscent of the “yay NFTs” phase of the crypto boom… *runs for cover*
Well, we can certainly agree that there should be more economic value in “voodoo AI that does stuff” than “monkey jpegs”. So let’s not stand by and watch the dreamy potential of our agentic1 overlords get squandered by the agent bro2 hype brigade, lest we all end up in that worst hell for product builders: a scathing MKBHD review. Let’s bring order to the chaos, starting with a taxonomy that shall hopefully become the common ground upon which magnificent works shall be built. Think of it as a dusty old treasure map tracing an adventure from "glorified autocomplete" to "potentially terrifying super-intelligence" - with all the exciting pit stops in between.
Our framework, PARMeSAN, outlines seven levels of AI systems, each building upon the capabilities of its predecessor. This aligns with Andrew Ng's perspective that "there are different degrees to which systems can be agentic", offering a spectrum of capabilities rather than a binary classification. The goal here is clarity and comprehension over completeness. The primary audience is folks who understand the basics of LLMs and RAG, but get fuzzy around how agents actually work and what do they really do. This post will give you a good mental model to work off of and start asking more pointed questions to the next agent bro that comes along.
The secondary audience is folks who, like me, have been working on agents for a while and feel there’s too much chaos in this space. If this is you, none of this post will be new information per se, but ideally this helps structure your day-to-day discussions a little better.3 The framework is meant to spark conversation and not be a definitive answer by any means. So if you feel weird in your stomach about anything described here, or have a brilliant suggestion, please send that over to /dev/null… err, to me. Send that to ME!
Now let’s jump in!
PARMeSAN
The PARMeSAN framework consists of 7 capabilities that constitute an AI Agent: (P)lanning, (A)ctions, (R)etrieval, (Me)mory, (S)ynthesis, (A)sync and I(N)trospection. Alongside, there are 7 archetypes, each adding a new capability over its predecessor, which qualitatively changes the scope of system, by roughly an order of magnitude, building upwards from plain LLMs to agents.
This framework lets us arrive at a crisp definition of an agent: Agents are digital entities that make plans, take actions on other systems to retrieve and commit information, learn from memories of past interactions, synthesize outputs to meet the user's need, execute tasks asynchronously when required, and introspect over their own work to continuously optimize their processes and potentially discover new knowledge.
The framework does not necessarily impose opinion on how the agentic capabilities are implemented: they could be emergent from pre-training a large foundation model or they could be engineered as (thick) wrappers on top of said pre-trained model, or be somewhere in between. The important consideration is how the system behaves for an end user, and what product value can be expected from the system at different levels.
See the table for a summary:

Level 0: The Know-it-all is plain LLM and Level 1: The Bookworm is RAG, which serve as baselines with no agentic behavior. The breakout Gen AI products of the last couple years fall into these categories. These levels are well studied by now and properly understood by the industry (I hope!). Innovation continues to occur in these levels, e.g. Claude’s new Artifacts feature classifies as Level 0.
Level 2: The Hustler is where things start to get interesting: we add the ability to invoke external tools via API calls, which is a core capability for any agentic behavior. However the system is still primitive and cannot handle complex tasks just yet. Level 3: The Strategist and Level 4: The Prodigy layer on the important capabilities of planning and memory, which enable the system to deal with larger scoped tasks.
Level 5: The Maestro is where we introduce asynchronous execution, which is a critical piece for the system to be seen as agentic, since it enables execution of long running tasks without constant human supervision. Level 6: The Sage is the final level to round up our framework, by adding the ability to introspect on its own processes and come up with improvements. We can debate whether this final piece is necessary for a system to be called an agent or if it goes beyond our current expectations from them. But hey, work in AI long enough and you get used to the moving of goalposts, so we might as well keep this in as insurance.
Now let’s study each level in more detail.
Level 0: The Know-it-all (Plain LLM)
Core Capability: Synthesis (S) - The ability to generate coherent and contextually relevant responses to user input, based on pre-trained information.
Products like ChatGPT, Bard and Claude revolutionized the way we interact with AI, demonstrating the potential of large language models (LLMs) to engage in human-like conversations and assist with a wide range of tasks. These products were a massive innovation when they originally came out, yet they now seem quite quaint compared to all the advancements in the ~20 months since: literally all they did was to pass user input to an LLM and stream back the output!4

How to test for this archetype: The system’s performance is entirely dependent on its pre-training, with no ability to access external information or update its knowledge base, hence the archetype is named Know-it-all. The first products only supported text (and code), but more recently they are powered by multimodal models that support passing images, audio and video via input, and in some cases also generating those on the output side. We would still classify them under Level 0 if there is no interaction with the external world beyond the user provided inputs and the model’s outputs.
These Know-it-all products made advanced AI capabilities accessible to the general public, sparking widespread interest and adoption. Conversational interfaces became a preferred method for interacting with AI systems. They also raised important questions about AI bias, misinformation, and the need for responsible AI development. However, bounded by training data cutoff, these models are prone to hallucinations when asked about information beyond their training scope. This takes us to the next level.
Level 1: The Bookworm (RAG)
New Capability: Retrieval (R) - Combine a language model with a retrieval mechanism to fetch up-to-date information and let the model use that information in the synthesis of its response.
A simple-yet-clever trick (love those!) to solve for the knowledge cutoff problem of Know-it-alls is to dynamically fetch information that might be relevant to the query, and feed it to the LLM as additional context during inference. LLMs have shown to be quite effective at leveraging such in-context information to tailor the synthesized response to be more grounded in the retrieved facts. This is the essence of RAG, or Retrieval-Augmented Generation, which we call The Bookworm archetype.
Products like Gemini, Google SGE, Perplexity, ChatGPT w/ Browser, and others have significantly enhanced the utility of AI assistants by integrating real-time information retrieval to provide more factual responses. Enterprise products like Gemini Enterprise, Glean, Harvey, Hebbia and many others have done the same, except with fetching documents from private repositories (e.g. Google Drive) or paid sources (e.g. legal case transcripts).
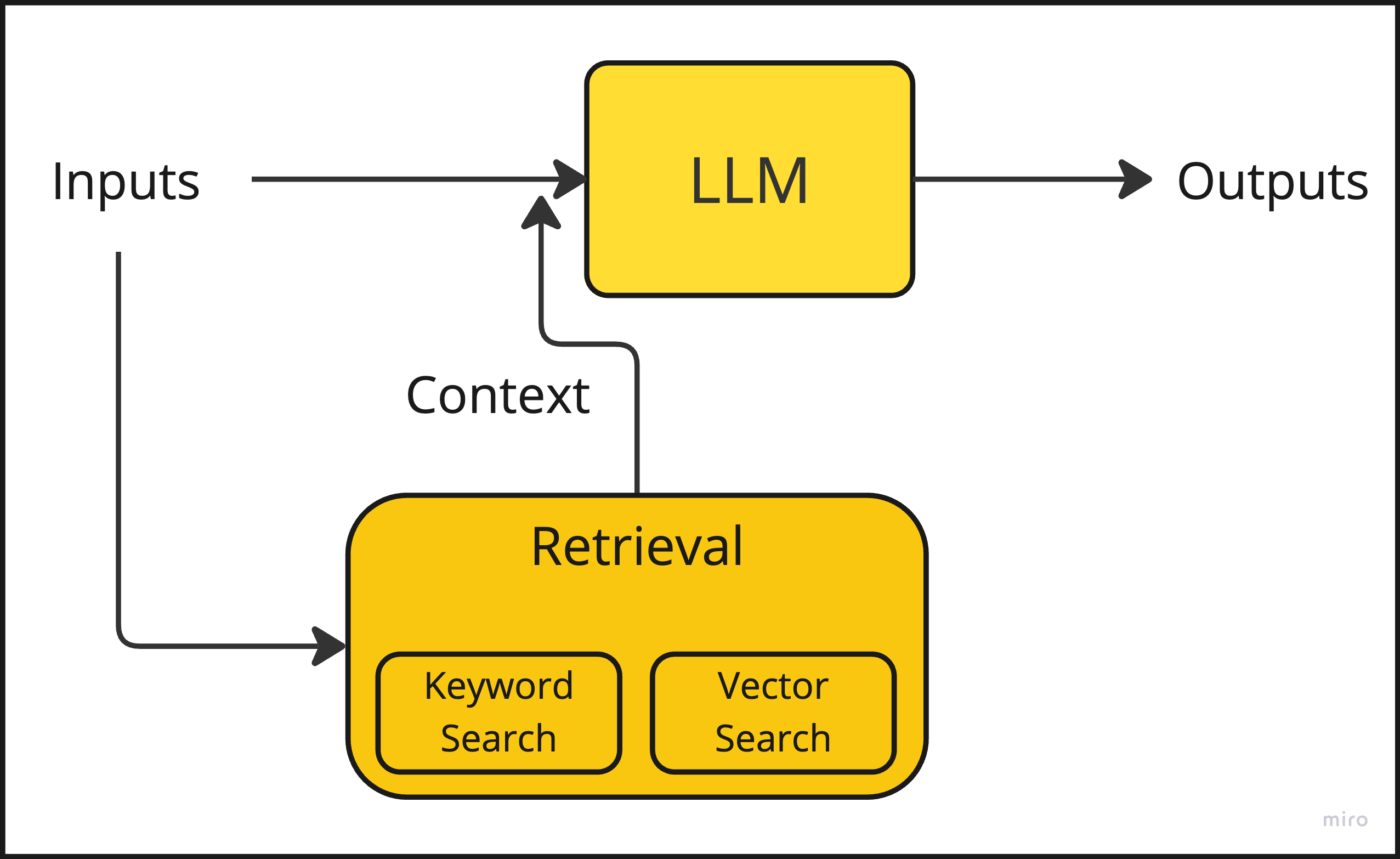
How to test for this archetype: The system incorporates some form of retrieval during runtime, i.e. LLM inference. Typically this is either traditional keyword search that finds documents with words similar to the user’s input, or vector search, which converts documents and user input into numerical vectors, then finds matches based on their similarity in this mathematical space. Most production systems use a hybrid of the two approaches.
Retrieval has mainly three parts:
Query construction: Create a keyword search query from the user input, or map the input to a vector search query.
Search and ranking: Execute the search on the database and rank the resulting documents.
Context augmentation: Take the top-N documents and paste their contents to the input prompt during LLM inference. There is some art (“prompt poetry”) involved in effectively augmenting the prompt for maximal performance.
Bookworm systems have greatly reduced the problem of hallucinations in AI responses, increasing trust and reliability. The ability to incorporate user-specific documents has opened new possibilities for personalized AI assistance in various domains. However, they are limited to only generating outputs directed towards the user, and cannot control other systems. This takes us to the next level.
Level 2: The Hustler (Tool-Use)
New Capability: Actions (A) - The system can make API calls to control other systems, reasoning over their outputs and using that in its own synthesis.
While Bookworms can retrieve and incorporate information, Hustlers can actually do something about it. This archetype introduces the concept of "tool use," allowing the AI to interact with a variety of external systems and APIs to perform actions beyond text/media generation. Products like ChatGPT with Plugins, Gemini with Extensions (I worked on this!), Function Calling support in popular LLM APIs, and various GPTs and LangChain apps have expanded the practical applications: these systems can now perform tasks such as looking up flights and hotels, analyzing data, or even controlling smart home devices.
The key innovation (another simple-yet-clever trick) is to change the LLM’s role from a single-shot output synthesizer to a smart control loop that decides whether to invoke a tool, which tool to call, what parameters to pass to it, and how to process the tool’s response into the final system output. The entire prompt is redesigned to coax the LLM to make these higher level decisions, in addition to also consuming relevant context from retrieval5 and synthesizing the final output as before.
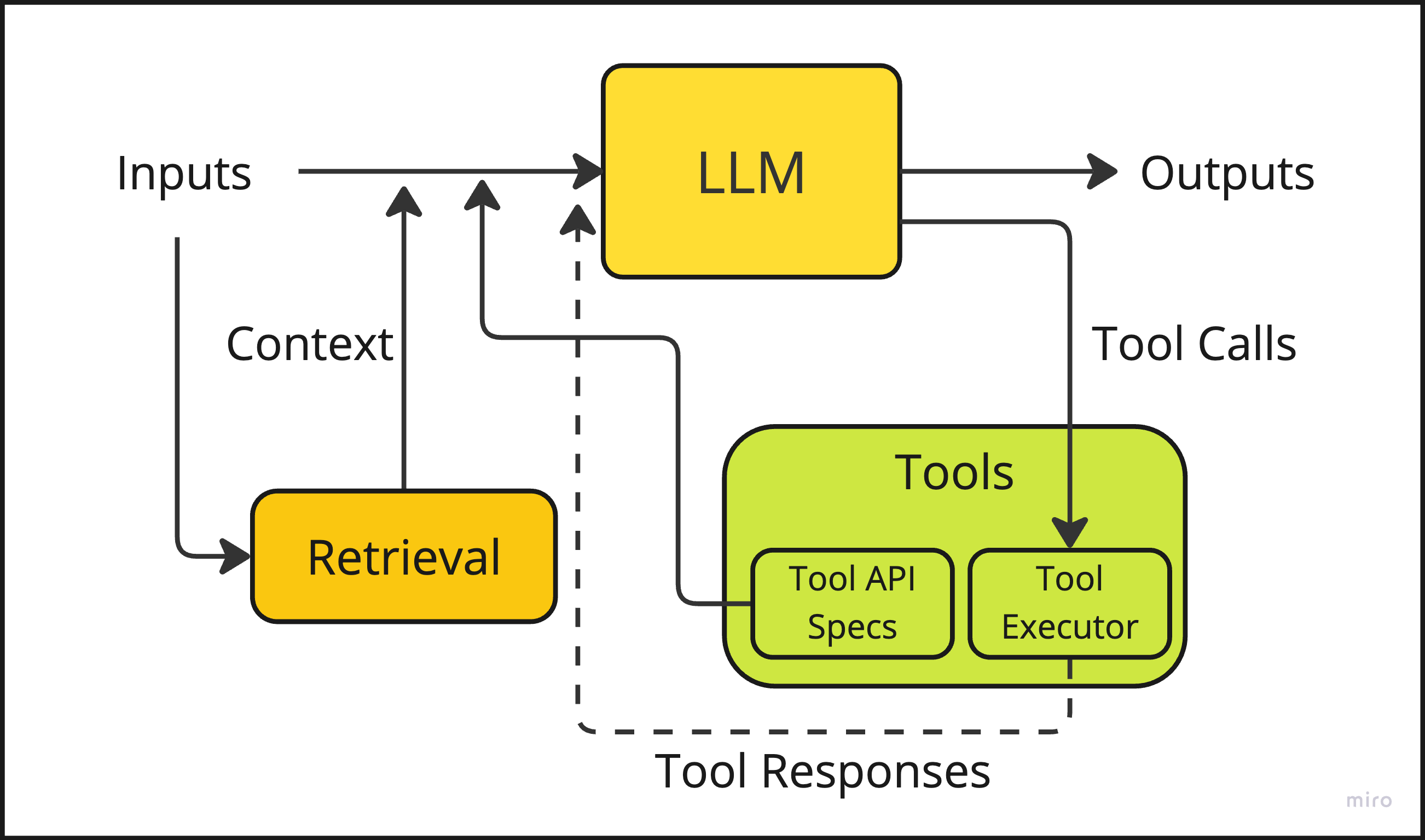
How to test for this archetype: The system allows for registering a number of tools (also referred to as “functions” - same thing) which can be invoked during the processing of a user request. Typically, the tool definitions (API specs) are shown upfront to the model as part of the prompt, in addition to the inputs and the retrieved context, so the model is aware of what tools are available for use. Then the model is instructed, via few-shot prompting or fine-tuning or both, to emit tool calls whenever appropriate.
A prompting approach that initially became quite popular is ReAct, short for Reason-and-Act, which forced to model to emit sequences of Thoughts (internal reasoning of what action it should take) and Actions (parameterized function calls that specify the tool invocation), which follows the chain-of-thought prompting mechanism to improve the model’s ability to pick the best actions. Other prompting approaches (Toolformer, CodeAct) have been explored as well.
The tool-use process typically involves:
Tool selection: Analyzing the user's request and determining which tool(s) might be needed. The available tools are provided in the prompt along with a specification of how to invoke them (i.e. parameters and their data types).
Action formulation: Constructing the appropriate API call or command for the selected tool. This is the step which requires most careful handling, because the model needs to properly encapsulate all the pieces of information so far into a correct API call.
Execution: Sending the command to the external tool and awaiting results. This requires necessary infrastructure to be in place to execute tools in a sandbox (to avoid security concerns from prompt injection, for instance) and deal with errors, retries, etc.
Result interpretation: Processing the tool's output and incorporating it into the overall response. Typically, the tool output is pasted verbatim into the context as part of the conversation history and the model is asked to decide how to proceed. But there could be a separate summarization step before passing the tool outputs to the model.
Hustler systems have significantly expanded the range of tasks AI can assist with, from simple calculations to complex data analysis and real-world interactions. The ability to interact with external tools has opened up the possibility of workflow automation, potentially reshaping various industries. However, in practice, they lack the ability to effectively plan sequences of actions for more complex tasks. We found that users very quickly hit the ceiling of what Hustler systems can do because even somewhat complex requests can lead the system astray as the probability of error multiplies with longer chains of tool calls. This limitation leads us to our next level.
Level 3: The Strategist (Planner / Multi-Step Reasoning)
New Capability: Planning (P) - The system can create and execute multi-step plans to achieve complex goals, by breaking down tasks into manageable steps.
Unlike the Hustler, which can use tools but lacks long-term strategy, the Strategist can break down complex tasks into a series of simpler steps, each potentially involving different tools or actions. Products like Perplexity Pro, DeepMind's Astra, and other emerging systems in this category are pushing the boundaries of AI problem-solving capabilities. These systems can tackle more intricate challenges that require a sequence of actions and logical reasoning.
The underlying innovation is yet another simple-but-clever trick (you should be used to them by now): let the LLM explicitly keep track of its plans by first having it verbalize the plan as a chain-of-thought, then tracking that plan as part of the prompt context in subsequent calls to the model, allowing it to make edits to the plan as needed. A good foundational paper to read on this is Plan-and-Solve prompting, which is also described well in this LangChain blog on Planning Agents.
If this sounds like a gross over-simplification, well it is. There’s a lot more careful design needed, for example, to deal with convoluted system states when things are not going according to plan, and setting up the right guardrails to let the effectively system recover from those. In addition, the standout products in this category will need a heavy lift on the UX layer, since all the additional complexity needs to be communicated effectively to the user, striking the right balance between keeping the user informed and making them feel overwhelmed.
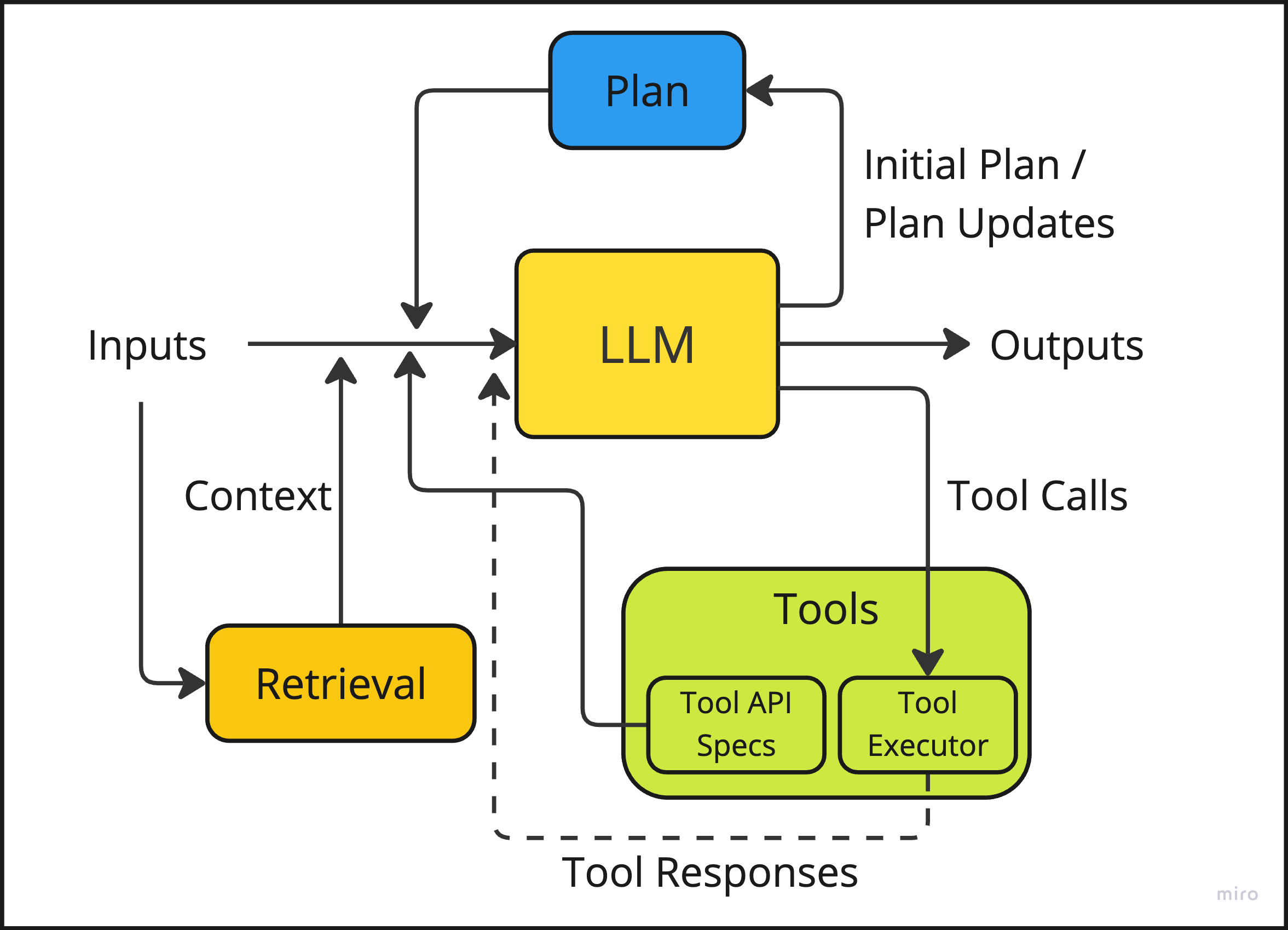
How to test for this archetype: The system should demonstrate:
Task decomposition: Breaking down a complex goal into smaller, manageable subtasks. This requires advanced techniques that go beyond simple tool-use.
Sequential planning: Ordering subtasks logically to achieve the overall goal. This requires a robust orchestration framework to manage multi-step, graph-dependency workflows.
Adaptive execution: Adjusting the plan based on intermediate results or changing conditions. Needs mechanisms for intermediate result evaluation and plan adjustment.
Result synthesis: Combining the outcomes of all subtasks into a coherent final result.
Meta-cognition (baby steps): Reasoning about its own problem-solving process and explaining its strategy to the user.
Strategist systems enable AI to tackle more complex, multi-step problems, potentially revolutionizing fields like scientific research, strategic planning, and complex decision-making processes. However, they still lack the ability to learn and adapt from long-term interactions or to run tasks asynchronously, which brings us to the next levels of agent capabilities.
That’s enough tokens for today! I will finish the rest of the deep dive in Part 2 which will include more thoughts on Level 3, and all of Levels 4, 5 and 6. Subscribe to get it in your inbox as soon as its published.
I don’t know who coined this word but I guess you got to roll with the times. At this point, I won’t be surprised if “agentic” is the Oxford word of the year for 2024.
Agent bros are like crypto bros, except that they swear by langchains not blockchains.
If you do not identify in either of these groups and yet found yourself on my blog and plan to continue reading it, please write to me about yourself and your thoughts on this post, and I will try to tailor my future writing towards you as well.
Of course, I’m sweeping a *lot* under the rug here, but bear with me. The broader point is that there’s so much more built on the shoulders of that initial Big Bang moment in late 2022.
There’s a variant of retrieval which some people call “agentic retrieval”, whereby the query construction phase of the retrieval step is undertaken by the main LLM itself, i.e. the retrieval is more actively guided by the model instead of a separate (simpler) system doing it. We can view this as just another “tool call” in the Hustler system. The benefit is you usually get a more precise query for the retrieval step, downside is the cost of an extra LLM call. In some cases, this tradeoff is worth it.
Thanks Pararth Sir for this.It's bit longer to read but worthwhile reading.